이미지 마이그레이션 계획
Cloudinary 관련 컨텐츠로 글을 무지막지하게 뽑아내고 있다. 처음에는 소소하게 시작했는데, 하다보니깐 재미가 붙어서 계속 살을 덧붙이고 싶어진다.
지금까지 내가 블로그에 올린 asset 파일들은 이 포스팅에서도 설명했다시피 두 가지 방식으로 저장했었는데, 이제는 이 파일들을 모두 Cloudinary로 마이그레이션 하고자 한다. 이를 위해 웹 스크래핑 라이브러리 Selenium을 사용해보기로 했다. 나도 Selenium은 이번에 처음 접해보기 때문에 Cursor의 힘을 빌려서 자동화 코드를 작성해보려 한다. 마이그레이션은 총 4단계로 이뤄진다.
- 블로그에 올린 이미지 파일의 경로 추출
- 추출한 경로를의 이미지를 모두 다운로드
- 다운로드한 이미지를 Cloudinary에 업로드
- 업로드된 경로를 바탕으로 기존 경로 수정
1. 블로그에 올린 이미지 파일의 경로 추출
우선 내 블로그(juheon.dev)에 접속하여 존재하는 모든 게시물에 있는 <img>태그 안의 src 속성을 추출해내야 한다. 추출한 이미지는 별도의 txt 파일로 저장해두고 이후 다운로드 과정에서 사용할 것이다.
코드는 Cursor가 열심히 만들어줬다. Cusor는 정말 최고다...짜릿하다....
코드 보기
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
import time
from datetime import datetime
def get_all_image_sources(driver, post_url):
# 게시물 페이지 접속
driver.get(post_url)
time.sleep(2) # 페이지 로딩 대기
# 이미지 태그 찾기
images = driver.find_elements(By.TAG_NAME, "img")
image_sources = []
# 이미지 소스 URL 추출
for img in images:
src = img.get_attribute('src')
if src:
image_sources.append(src)
return image_sources
def save_to_file(image_sources):
# 현재 시간을 파일명에 포함
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"image_sources_{timestamp}.txt"
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"추출 시간: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"총 이미지 수: {len(image_sources)}\n")
f.write("-" * 50 + "\n\n")
for i, src in enumerate(image_sources, 1):
f.write(f"{i}. {src}\n")
return filename
def main():
# Chrome 드라이버 설정
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
try:
# 메인 페이지 접속
driver.get("https://juheon.dev")
time.sleep(3) # 페이지 로딩 대기
# 모든 게시물 링크 수집
post_links = []
articles = driver.find_elements(By.TAG_NAME, "article")
for article in articles:
try:
link = article.find_element(By.TAG_NAME, "a").get_attribute('href')
if link:
post_links.append(link)
except:
continue
print(f"총 {len(post_links)}개의 게시물을 찾았습니다.")
# 각 게시물 방문하여 이미지 소스 추출
all_image_sources = []
for i, post_url in enumerate(post_links, 1):
print(f"\n게시물 {i}/{len(post_links)} 처리 중...")
image_sources = get_all_image_sources(driver, post_url)
print(f"발견된 이미지 수: {len(image_sources)}")
for src in image_sources:
print(f"이미지 소스: {src}")
all_image_sources.append(src)
# 결과를 파일로 저장
filename = save_to_file(all_image_sources)
print(f"\n총 {len(all_image_sources)}개의 이미지를 찾았습니다.")
print(f"결과가 {filename} 파일에 저장되었습니다.")
finally:
driver.quit()
if __name__ == "__main__":
main()
2. 추출한 경로를의 이미지를 모두 다운로드
1번을 실행하면 아래와 같은 형태의 텍스트 파일이 생성된다. 그럼 이제 이 파일을 모두 다운로드해야 한다. 여기서 주의해야할 점은 jpg 파일과 gif 파일이 혼재되어 있기 때문에 파일 확장자를 확인하여 다운로드해야 한다.
추출 시간: 2025-01-27 21:43:56
총 이미지 수: 104
--------------------------------------------------
4. https://juheon.dev/static/d059a7dc2274b3319003d03e50db9fcd/bbf83/profile-graduate.jpg
14. https://github.com/user-attachments/assets/4d1c7159-9a23-4473-a039-7bfe3375bf2c
18. https://github.com/user-attachments/assets/d9ad8b41-fb62-4469-a1bd-0f278b6d13f4
...
Response 헤더를 통해 확장자가 gif인지 jpg인지 확인할 수 있다. 또한 경로가 juheon.dev/static/ 이거나 github.com/user-attachments/ 인 경우에만 다운로드하도록 하면 된다. 다운로드한 파일은 /images 디렉토리에 저장된다.
코드 보기
import os
import requests
from urllib.parse import urlparse
import re
from pathlib import Path
def get_image_format(response):
"""
이미지 데이터를 분석하여 실제 이미지 포맷을 반환
"""
# 처음 바이트를 확인하여 이미지 포맷 판별
header = response.content[:8]
# GIF 시그니처 확인
if header.startswith(b'GIF89a') or header.startswith(b'GIF87a'):
return 'gif'
# JPEG 시그니처 확인
elif header.startswith(b'\xFF\xD8\xFF'):
return 'jpg'
return 'jpg' # 기본값은 jpg
def download_image(url, save_dir):
try:
# URL에서 파일명 추출
parsed_url = urlparse(url)
filename = os.path.basename(parsed_url.path)
# 파일명에서 모든 확장자 제거
name = filename.lower().replace('.jpg', '').replace('.jpeg', '').replace('.gif', '')
# 이미지 다운로드 및 포맷 확인
response = requests.get(url, stream=True)
response.raise_for_status()
# 실제 이미지 포맷 확인
image_format = get_image_format(response)
filename = name + '.' + image_format
# 저장 경로 설정
save_path = os.path.join(save_dir, filename)
# 파일 저장
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
print(f"다운로드 완료: {filename} ({image_format} 포맷)")
return True
except Exception as e:
print(f"다운로드 실패 ({url}): {str(e)}")
return False
def main():
# images 디렉토리 생성
save_dir = 'images'
os.makedirs(save_dir, exist_ok=True)
# 가장 최근의 image_sources 파일 찾기
image_sources_files = list(Path('.').glob('image_sources_*.txt'))
if not image_sources_files:
print("image_sources 파일을 찾을 수 없습니다.")
return
latest_file = max(image_sources_files, key=os.path.getctime)
print(f"파일 처리 중: {latest_file}")
# 파일에서 URL 읽기
with open(latest_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
# URL 필터링 및 다운로드
patterns = [
r'juheon\.dev/static/',
r'github\.com/user-attachments/'
]
success_count = 0
total_count = 0
for line in lines:
# URL 추출 (번호. URL 형식에서)
match = re.search(r'\d+\.\s*(http[^\s]+)', line)
if not match:
continue
url = match.group(1)
# 지정된 패턴과 일치하는 URL만 처리
if any(re.search(pattern, url) for pattern in patterns):
total_count += 1
if download_image(url, save_dir):
success_count += 1
print(f"\n다운로드 완료: {success_count}/{total_count} 파일")
print(f"저장 위치: {os.path.abspath(save_dir)}")
if __name__ == "__main__":
main()
dd
실행해보면 파일들이 모두 저장된 것을 확인할 수 있다!
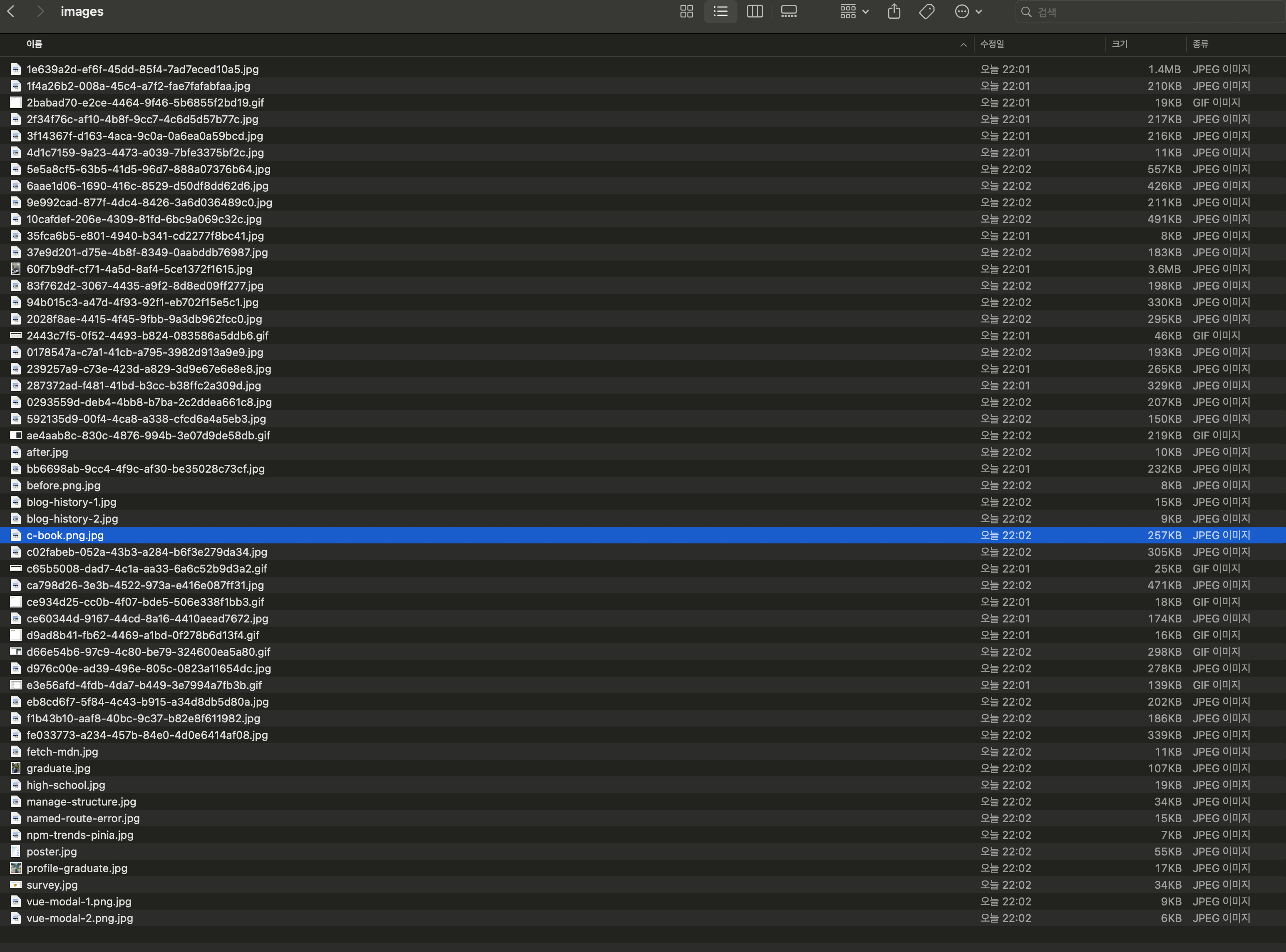
3. 다운로드한 이미지를 Cloudinary에 업로드
이제 이 파일들을 Cloudinary에 업로드해야 한다. 이 단계는 Drag & Drop 방식으로 옮기기만 하면 되기 때문에 매우 간단하다.
4. 업로드된 경로를 바탕으로 기존 경로 수정
이제 Cloudinary에 업로드된 이미지들을 바탕으로 기존 경로를 수정해야 한다. 이 단계는 모두 수작업으로 해야 한다. 때문에 이전 3개의 단계를 합친 시간보다도 더 품이 드는 작업이다. Cursor로도 자동화를 해보려고 했는데, 잘 인식이 안되는 것 같다.
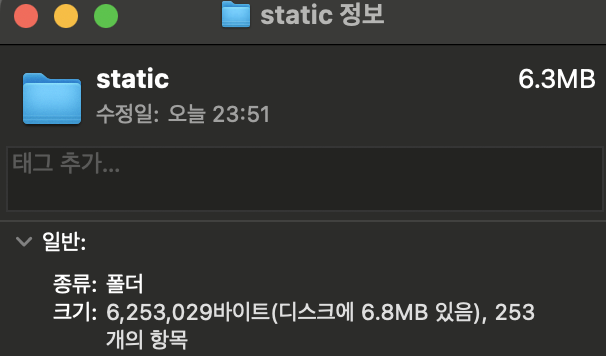
마이그레이션 결과
빌드 결과물을 확인해본 결과, asset 파일의 용량이 기존 28.4 MB에서 70% 이상 줄어든 6.3MB가 된 것을 확인할 수 있다. 앞으로 블로그에 올린 이미지들은 모두 Cloudinary에 저장될 것이다.